> For the complete documentation index, see [llms.txt](https://docs.bluekeys.org/guide/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.bluekeys.org/guide/nouveautes/netflix-technologies/how-netflix-scales-its-api-with-graphql-federation-part-1.md).
# How Netflix Scales its API with GraphQL Federation (Part 1)
[Netflix Technology Blog](https://medium.com/@NetflixTechBlog?source=post_page-----ae3557c187e2--------------------------------) [Nov 9](https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-1-ae3557c187e2?source=post_page-----ae3557c187e2--------------------------------) · 9 min read

Netflix is known for its loosely coupled and highly scalable microservice architecture. Independent services allow for evolving at different paces and scaling independently. Yet they add complexity for use cases that span multiple services. Rather than exposing 100s of microservices to UI developers, Netflix offers a unified API aggregation layer at the edge.
UI developers love the simplicity of working with one conceptual API for a large domain. Back-end developers love the decoupling and resilience offered by the API layer. But as our business has scaled, our ability to innovate rapidly has approached an invisible asymptote. As we’ve grown the number of developers and increased our domain complexity, developing the API aggregation layer has become increasingly harder.
In order to address this rising problem, we’ve developed a federated GraphQL platform to power the API layer. This solves many of the consistency and development velocity challenges with minimal tradeoffs on dimensions like scalability and operability. We’ve successfully deployed this approach for Netflix’s studio ecosystem and are exploring patterns and adaptations that could work in other domains. We’re sharing our story to inspire others and encourage conversations around applicability elsewhere.
## Case Study: Studio Edge
**Intro to** [**Studio Ecosystem**](https://netflixtechblog.com/netflix-studio-engineering-overview-ed60afcfa0ce)
Netflix is producing original content at an accelerated pace. From the time a TV show or a movie is pitched to when it’s available on Netflix, a lot happens behind the scenes. This includes but is not limited to talent scouting and casting, deal and contract negotiations, production and post-production, visual effects and animations, subtitling and dubbing, and much more. Studio Engineering is building hundreds of applications and tools that power these workflows.Content Lifecycle


## Studio API
Looking back to a few years ago, one of the pains in the studio space was the growing complexity of the data and its relationships. The workflows depicted above are inherently connected but the data and its relationships were disparate and existed in myriads of microservices. The product teams solved for this with two architectural patterns.
1\) Single-use aggregation layers — Due to the loose coupling, we observed that many teams spent considerable effort building duplicative data-fetching code and aggregation layers to support their product needs. This was either done by UI teams via BFF (Backend For Frontend) or by a backend team in a mid-tier service.
2\) Materialized views for data from other teams — some teams used a pattern of [building a materialized view](https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view) of another service’s data for their specific system needs. Materialized views had performance benefits, but data consistency lagged by varying degrees. This was not acceptable for the most important workflows in the Studio. Inconsistent data across different Studio applications was the top support issue in Studio Engineering in 2018.
**Graph API:** To better address the underlying needs, our team started building a curated graph API called “Studio API”. Its goal was to provide an unified abstraction on top of data and relationships. Studio API used [GraphQL](https://graphql.org/learn/) as its underlying API technology and created significant leverage for accessing core shared data. Consumers of Studio API were able to explore the graph and build new features more quickly. We also observed fewer instances of data inconsistency across different UI applications, as every [field in GraphQL](https://graphql.org/learn/execution/) resolves to a single piece of data-fetching code.**Studio API Graph****Studio API Architecture**


## Bottlenecks of Studio API
The [*One Graph*](https://principledgraphql.com/integrity#1-one-graph) exposed by Studio API was a runaway success; product teams loved the reusability and easy, consistent data access. But new bottlenecks emerged as the number of consumers and amount of data in the graph increased.
First, the Studio API team was disconnected from the domain expertise and the product needs, which negatively impacted the schema’s health. Second, connecting new elements from a back-end into the graph API was manual and ran counter to the rapid evolution promised by a microservice architecture. Finally, it was hard for one small team to handle the increasing operational and support burden for the expanding graph.
We knew that there had to be a better way — unified but decoupled, curated but fast moving.
## Returning to Core Principles
To address these bottlenecks, we leaned into our [rich history](https://smartbear.com/blog/develop/why-you-cant-talk-about-microservices-without-ment/) of microservices and breaking monoliths apart. We still wanted to keep the unified GraphQL schema of Studio API but decentralize the implementation of the resolvers to their respective domain teams.
As we were brainstorming the new architecture back in early 2019, Apollo released the [GraphQL Federation Specification](https://www.apollographql.com/docs/apollo-server/federation/federation-spec/). This promised the benefits of a unified schema with distributed ownership and implementation. We ran a test implementation of the spec with promising results, and reached out to collaborate with Apollo on the future of GraphQL Federation. Our next generation architecture, “Studio Edge”, emerged with federation as a critical element.
### GraphQL Federation Primer
The goal of GraphQL Federation is two-fold: provide a unified API for consumers while also giving backend developers flexibility and service isolation. To achieve this, schemas need to be created and annotated to indicate how ownership is distributed. Let’s look at an example with three core entities:
1. **Movie**: At Netflix, we make titles (shows, films, shorts etc.). For simplicity, let’s assume each title is a **Movie** object.
2. **Production**: Each **Movie** is associated with a Studio Production. A **Production** object tracks everything needed to make a **Movie** including shooting location, vendors, and more.
3. **Talent**: the people working on a **Movie** are the **Talent**, including actors, directors, and so on.
These three domains are owned by three separate engineering teams responsible for their own data sources, business logic, and corresponding microservices. In an unfederated implementation, we would have this simple Schema and [Resolvers](https://medium.com/paypal-engineering/graphql-resolvers-best-practices-cd36fdbcef55) owned and implemented by the Studio API team. The GraphQL Framework would take in queries from clients and orchestrate the calls to the resolvers in a breadth-first traversal.**Schema & Resolvers for Studio API**

To transition to a federated architecture, we need to transfer ownership of these resolvers to their respective domains without sacrificing the unified schema. To achieve this, we need to extend the **Movie** type across GraphQL service boundaries:**Federating Movie**


This ability to extend a **Movie** type across GraphQL service boundaries makes **Movie** a **Federated Type**. Resolving a given field requires delegation by a gateway layer down to the owning domain services.
## Studio Edge Architecture
Using the ability to federate a type, we envisioned the following architecture:**Studio Edge Architecture**

### Key Architectural Components
**Domain Graph Service (DGS)** is a standalone [spec-compliant](https://spec.graphql.org/June2018/) GraphQL service. Developers define their own federated GraphQL schema in a DGS. A DGS is owned and operated by a domain team responsible for that subsection of the API. A DGS developer has the freedom to decide if they want to convert their existing microservice to a DGS or spin up a brand new service.
**Schema Registry** is a stateful component that stores all the schemas and schema changes for every DGS. It exposes CRUD APIs for schemas, which are used by developer tools and CI/CD pipelines. It is responsible for schema validation, both for the individual DGS schemas and for the combined schema. Last, the registry composes together the unified schema and provides it to the gateway.
**GraphQL Gateway** is primarily responsible for serving GraphQL queries to the consumers. It takes a query from a client, breaks it into smaller sub-queries (a query plan), and executes that plan by proxying calls to the appropriate downstream DGSs.
### Implementation Details
There are 3 main business logic components that power GraphQL Federation.
**Schema Composition**
Composition is the phase that takes all of the federated DGS schemas and aggregates them into a single unified schema. This composed schema is exposed by the Gateway to the consumers of the graph.Schema Composition Phases

Whenever a new schema is pushed by a DGS, the Schema Registry validates that:
1. New schema is a valid GraphQL schema
2. New schema composes seamlessly with the rest of the DGSs schemas to create a valid composed schema
3. New schema is backwards compatible
If all of the above conditions are met, then the schema is checked into the Schema Registry.
**Query Planning and Execution**
The federation config consists of all the individual DGS schemas and the composed schema. The Gateway uses the federation config and the client query to generate a query plan. The query plan breaks down the client query into smaller sub-queries that are then sent to the downstream DGSs for execution, along with an execution ordering that includes what needs to be done in sequence versus run in parallel.Query Plan Inputs

Let’s build a simple query from the schema referenced above and see what the query plan might look like.Simplified Query Plan

For this query, the gateway knows which fields are owned by which DGS based on the federation config. Using that information, it breaks the client query into three separate queries to three DGSs. The first query is sent to Movie DGS since the root field **movies** is owned by that DGS. This results in retrieving the **movieId** and **title** fields for the first 10 movies in the dataset. Then using the **movieId**s it got from the previous request, the gateway executes two parallel requests to Production DGS and Talent DGS to fetch the **production** and **actors** fields for those 10 movies. Upon completion, the sub-query responses are merged together and the combined data response is returned to the caller.
> *A note on performance:* Query Planning and Execution adds a \~10ms overhead in the **worst case**. This includes the compute for building the query plan, as well as the deserialization of DGS responses and the serialization of merged gateway response.
**Entity Resolver**
Now you might be wondering, how do the parallel sub-queries to Production and Talent DGS actually work? That’s not something that the DGS supports. This is the final piece of the puzzle.
Let’s go back to our federated type **Movie**. In order for the gateway to join **Movie** seamlessly across DGSs, all the DGSs that define and extend the **Movie** need to agree on one or more fields that define the primary key (e.g. **movieId)**. To make this work, Apollo introduced the **@key** [directive](https://www.apollographql.com/docs/federation/entities/#defining) in the Federation Spec. Second, DGSs have to implement a resolver for a generic **Query** field, **\_entities.** The **\_entities** query returns a union type of all the federated types in that DGS. The gateway uses the **\_entities** query to look up **Movie** by **movieId.**
Let’s take a look at how the query plan actually looks likeDetailed Federated Query Plan
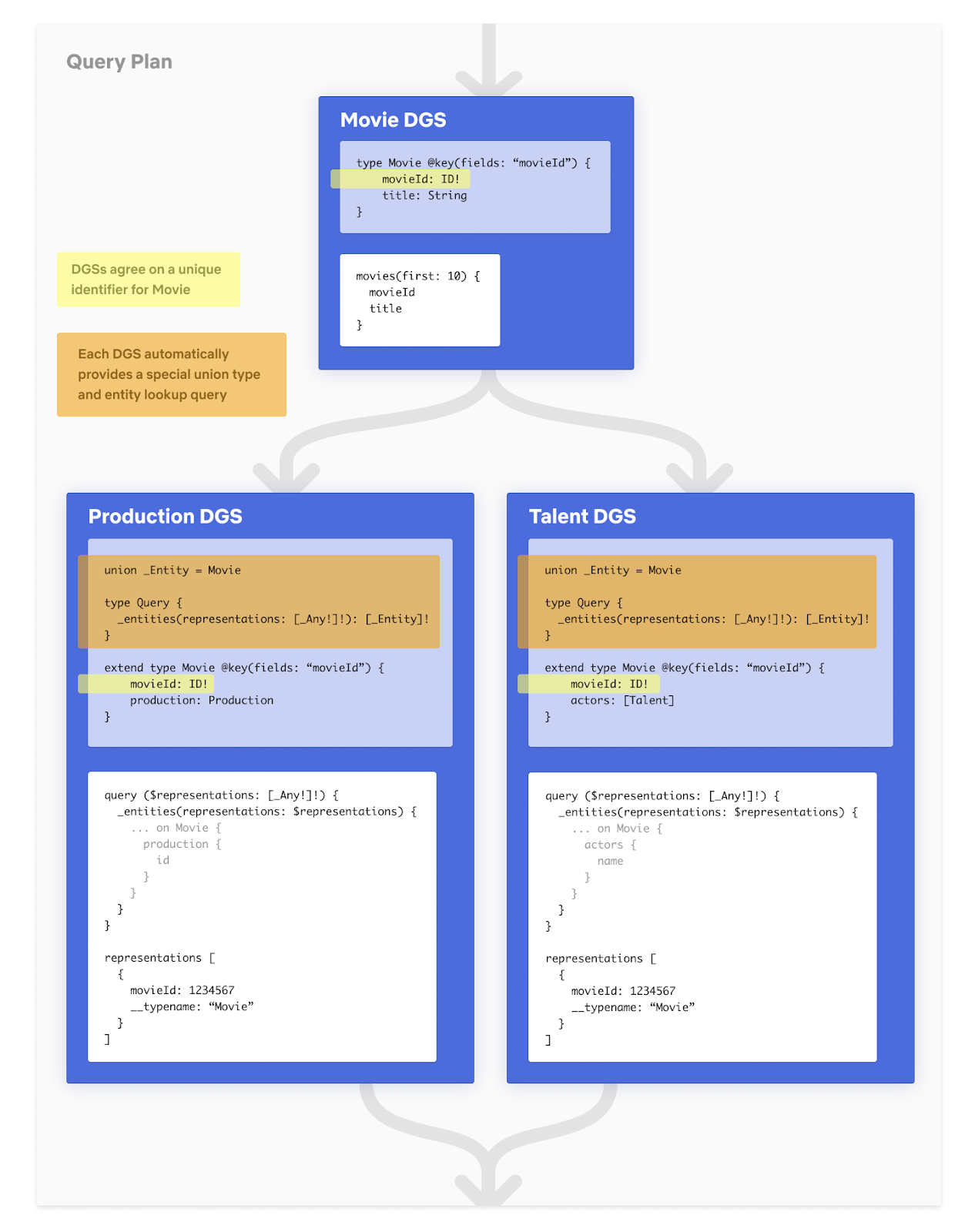
The representation object consists of the **movieId** and is generated from the response of the first request to Movie DGS. Since we requested for the first 10 movies, we would have 10 representation objects to send to Production and Talent DGS.
> This is similar to [Relay’s Object Identification](https://relay.dev/graphql/objectidentification.htm) with a few differences. ***\_Entity*** is a union type, while Relay’s ***Node*** is an interface. Also, with @key, there is support for variable key names and types as well as composite keys while in Relay, the id is a single opaque **ID** field*.*
Combined together, these are the ingredients that power the core of a federated API architecture.
## The Journey, Summarized
Our Studio Ecosystem architecture has evolved in distinct phases, all motivated by reducing the time between idea and implementation, improving the developer experience, and streamlining operations. The architectural phases look like:Evolution of an API Architecture

## Stay Tuned
Over the past year we’ve implemented the federated API architecture components in our Studio Edge. Getting here required rapid iteration, lots of cross-functional collaborations, a few pivots, and ongoing investment. We’re live with 70 DGSes and hundreds of developers contributing to and using the Studio Edge architecture. In our next Netflix Tech Blog post, we’ll share what we learned along the way, including the cross-cutting concerns necessary to build a holistic solution.
We want to thank the entire GraphQL open-source community for all the generous contributions and paving the path towards the promise of GraphQL. If you’d like to be a part of solving complex and interesting problems like this at Netflix scale, check out [our jobs page](https://jobs.netflix.com/) or reach out to us directly.
*By* [*Tejas Shikhare*](https://www.linkedin.com/in/tejas-shikhare-81027b19/)
*Additional Credits:* [*Stephen Spalding*](https://twitter.com/stephenspalding)*,* [*Jennifer Shin*](https://www.linkedin.com/in/jennifer-shin-0019a516/)*,* [*Philip Fisher-Ogden*](https://www.linkedin.com/in/philfish)*,* [*Robert Reta*](https://www.linkedin.com/in/robert-reta-a17b918/)*,* [*Antoine Boyer*](https://www.linkedin.com/in/antoineboyer/)*,* [*Bruce Wang*](https://www.linkedin.com/in/batmany13/)*,* [*David Simmer*](https://www.linkedin.com/in/simmerer/)
Source :