> For the complete documentation index, see [llms.txt](https://docs.bluekeys.org/guide/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.bluekeys.org/guide/cyber-securite/outils/introduction-au-reverse-engineering.md).
# Introduction au reverse engineering
### 1. Qu’est-ce que le « reverse engineering »
Le « reverse » n’est pas une activité strictement informatique : on peut penser à la formule du Coca-Cola qui a été analysée au spectrographe de masse, aux capsules de café dites « compatibles », à la fabrication d’accessoires pour l’iPhone 5 (dont Apple n’a pas publié les spécifications), etc.
À la limite de l’informatique, il existe également une forte activité autour du « reverse » de cartes électroniques, de *bitstreams* FPGA, voire de composants électroniques. Cette activité existe depuis fort longtemps, par exemple dans le domaine de la télévision sur abonnement (*Pay TV*), mais elle devient de plus en plus présente dans les conférences de sécurité, à mesure que la sécurité descend dans les couches matérielles via des TPM et autres processeurs « ad-hoc ». Portes d’hôtel, bus automobiles, microcode des cartes Wi-Fi, téléphones par satellite, femtocells, routeurs et autres équipements embarqués deviennent des objets d’étude pour les « hackers ». À titre anecdotique, on peut par exemple citer le projet 3DBrew **\[1]** qui compte « libérer » la console Nintendo 3DS en décapsulant le processeur Nintendo pour en extraire les clés privées par microscopie électronique.
Dans le domaine de la sécurité informatique, le « reverse » est souvent considéré comme le « Graal » des compétences, à la limite de la sorcellerie. Pénétrons donc dans le territoire des arts obscurs.
### 2. L’épine législative
La question récurrente liée à la pratique du « reverse » en France est légale : que risque-t-on à s’afficher publiquement « reverser » ? Le *Malleus Maleficarum* nous indique qu’il faut transpercer chaque grain de beauté du suspect à l’aide d’une aiguille : si la plaie ne saigne pas, nous sommes en présence d’un sorcier. Et je ne vous parle pas des techniques déployées par l’ANSSI …
« Je ne suis pas juriste », mais il me semble que la réponse à la question législative n’a aucune importance. Si vous êtes du côté lumineux de la Force – par exemple, que vous analysez des virus pour désinfecter un parc d’entreprise (voire que vous éditez un antivirus français) – ni l’auteur du virus, ni le procureur de la République ne vous inquiéteront pour ce fait.
Si par mégarde vous cheminez sur les sentiers obscurs du *cracking* et de *keygening*, vous passerez sous les fourches caudines de l’autorité publique pour un motif quelconque. N’oublions pas que dans la plus célèbre affaire judiciaire de « reverse » française – la société Tegam contre Guillermito – ce dernier a été condamné du fait qu’il n’avait pas acquis de licence pour le logiciel objet de son étude…
Le point juridique étant évacué, entrons désormais dans le vif du sujet.
### 3. « Reverse engineering » vs. « cracking »
Le vrai « reverse » est une discipline noble et exigeante. Elle consiste à comprendre entièrement un logiciel au point d’en produire une copie interopérable. Les exemples sont nombreux : projet Samba (dont la version 4 peut se substituer à un contrôleur de domaine Microsoft Active Directory), nombreux pilotes Linux et codecs, algorithme RC4 (republié en 1994 sous le nom de ARC4 pour « Alleged RC4 »), etc.
Il s’agit d’une activité très différente de la recherche et de l’exploitation de failles logicielles, ou du « déplombage » de logiciels commerciaux. Il est regrettable de recevoir de nombreux CV mentionnant la compétence « reverse engineering », alors que le candidat ne sait que suivre un flot d’exécution à la main dans son débogueur (technique dite du « F8 »), jusqu’à trouver l’instruction « JNZ » qui va contourner la quasi-totalité des systèmes de licence écrits « à la main ».
### 4. Bestiaire Monstrueux
Même en se limitant au logiciel informatique, la notion de « reverse » couvre un périmètre excessivement large : du code embarqué dans un microcontrôleur à une application Java, en passant par les « bonnes vieilles » applications en C.
Avant de traiter du cœur du sujet – à savoir les langages compilés (C/C++/Objective-C/…), feuilletons le reste du bestiaire que tout apprenti doit connaître.
#### 4.1 Assembleur
Les applications les plus bas niveaux (BIOS, *firmwares*, systèmes d’exploitation, jeux pour consoles archaïques, applications MS-DOS, etc.) sont généralement largement écrites en assembleur. Dans ce cas, il n’y a guère d’alternatives : il est strictement nécessaire de connaître très finement l’architecture de la plateforme matérielle cible, ainsi que les instructions du processeur réservées aux opérations bas niveau (initialisation matérielle, etc.).
Ce cas est généralement réservé à des spécialistes et ne sera pas couvert dans la suite de l’article.
#### 4.2 Bytecode
Plutôt que de livrer des applications compilées pour un processeur existant, certains environnements de développement compilent dans un langage intermédiaire de haut niveau, appelé « bytecode ». Un environnement d’exécution (la « machine virtuelle ») doit être fourni pour chaque plateforme matérielle sur laquelle doit s’exécuter ce langage intermédiaire.
Le lecteur éveillé pense immédiatement aux environnements Java et .NET, mais l’utilisation de « bytecode » est beaucoup plus répandue : on peut citer Flash ActionScript, Visual Basic 6 et son P-Code, les langages de script comme Python (fichiers PYC/PYO), mais aussi … les protections logicielles.
On peut disserter sans fin des avantages et des inconvénients d’un « bytecode » par rapport à du code « natif » d’un point de vue génie logiciel. Ce qui est sûr, c’est que la quasi-totalité des « bytecodes » qui n’ont pas été conçus dans une optique de protection logicielle se décompilent sans aucune difficulté sous forme de code source original. Je vous renvoie à vos outils favoris pour cette opération (JD-GUI pour Java, Reflector pour .NET, Uncompyle2 pour Python, etc.).
#### 4.3 Cas des protections logicielles
La protection logicielle est au reverse engineering ce que la nécromancie est à la divination : ce sont deux écoles qui procèdent selon les mêmes principes, mais que tout oppose. Et tandis que tout le monde consulte son voyant, peu nombreux sont ceux qui admettent lever les morts.
Néanmoins, il ne faut pas se mentir : l’étude des protections logicielles constitue la meilleure école pour apprendre rapidement le reverse engineering. Sites de « crackmes », tutoriels, outils, tout est là pour qui veut brûler les étapes. Plus rapide, plus séduisant, mais pas plus puissant est le « cracking ». Seule la maîtrise de l’algorithmique et de la théorie de la compilation permettra d’atteindre la transcendance.
Les protections logicielles sont généralement mises en œuvre pour protéger la gestion des licences logicielles, d’où le caractère sulfureux de leur analyse. Il faut noter toutefois qu’il existe d’autres cas d’usage, comme par exemple :
* La protection d’algorithmes contre l’analyse par des clients légitimes du logiciel (ex. Skype) ;
* La protection de codes malveillants contre l’analyse par les éditeurs antivirus (ex. rootkit TDL-4) ;
* La protection de « cracks » contre l’analyse par les éditeurs (ex. crack pour Windows Vista simulant un BIOS OEM **\[2]**).
Ces derniers cas légitiment grandement l’activité de reverse engineering des protections logicielles. Vous pouvez donc poursuivre la lecture de cet article sans craindre pour votre âme.
Une « bonne » protection doit résister aussi bien à l’analyse statique qu’à l’analyse dynamique de la cible. L’objet de cet article introductif n’est pas d’énumérer toutes les techniques mises au point dans le jeu du chat et de la souris entre « crackers » et éditeurs de protection, mais il existe *grosso modo* deux grandes classes de protections logicielles utilisées actuellement :
* Les protections externes (dites « packers »). Ces protections visent à « enrober » le logiciel original dans une couche de protection. Le logiciel est chiffré contre l’analyse statique. Il est déchiffré en mémoire à l’exécution, mais des protections anti-débogage et anti-dump permettent d’éviter une récupération trop facile du code.
* Les protections internes (dites « obfuscateurs »). Le principe est de réécrire le code assembleur du logiciel afin de le rendre inintelligible aux Moldus. Plusieurs techniques ont été expérimentées : transformation du code assembleur en bytecode (vulnérable à un « *class break* » si la machine virtuelle est analysée), insertion de code mort ou complexe à évaluer statiquement, réécriture du graphe de contrôle (« *code flattening* »), etc. Il s’agit d’un domaine de recherche très actif, y compris dans le monde académique.
À titre anecdotique, les systèmes de contrôle de licence sont à classer dans plusieurs catégories :
* Les protections matérielles (*dongles*) : très puissantes, mais assez rares aujourd’hui, sauf pour du logiciel très haut de gamme. Le principe consiste à déporter une partie des traitements dans un composant électronique (clé USB « intelligente ») supposé inviolable. Plus le traitement déporté est complexe, plus il sera difficile à comprendre en boîte noire. Un logiciel qui se contenterait de vérifier la présence du susdit *dongle* sans jamais s’en servir serait bien sûr condamné à finir sur Astalavista.
* Numéro de série ou fichier de licence : la cryptographie moderne autorise des schémas théoriquement inviolables, si l’implémentation est correcte. Mais même un système inviolable peut être piraté… en remplaçant la clé publique de l’éditeur dans le binaire !
* Activation en ligne : le logiciel vérifie qu’il dispose du droit de s’exécuter auprès d’un serveur tiers. Dans les cas les plus élaborés, une partie des traitements est effectuée en ligne – mais cette situation n’est pas toujours acceptable par le client.
### 5. Les Piliers du Temple
Entrons maintenant dans le vif du sujet : quelles sont les compétences requises pour s’attaquer à une application « native », compilée depuis un langage relativement courant (tel que le C) ?
De mon expérience, elles sont au nombre de quatre.
#### 5.1 Connaître l’assembleur cible
Il n’est absolument pas nécessaire de connaître par cœur le manuel de référence du processeur ! À titre d’exemple, le jeu d’instructions des processeurs x86 et x64 contient une majorité d’instructions en virgule flottante, rarement rencontrées et dont la sémantique est impossible à mémoriser.
Par ailleurs, les compilateurs n’utilisent qu’un sous-ensemble réduit du jeu d’instructions, comme on le verra plus tard.
Il est par contre de bon ton de connaître les spécifiés du processeur cible. Sur architectures x86 et x64, ce sont par exemple la segmentation et les registres implicites. Sur architecture SPARC ce sont les registres glissants et les « *delay slots* » (qu’on retrouve également sur MIPS). Il existe des architectures encore plus exotiques telles que les processeurs VLIW (*Very Long Instruction Word*).
#### 5.2 Savoir développer
N’oublions pas que le reverse engineering logiciel consiste à comprendre ce qu’a écrit le développeur d’origine. Il est donc fortement recommandé de savoir soi-même développer dans le langage cible…
Il est amusant de constater qu’il existe des modes dans les « *design patterns* ». Si le code Sendmail est truffé de constructions setjmp/longjmp/goto désormais obsolètes, le tout nouveau C++11 autorise bien d’autres acrobaties…
Par ailleurs, chaque développeur a ses lubies. Il ne s’agit donc pas de savoir programmer, mais d’avoir une idée de comment programment les autres… La lecture régulière de code issu de projets open source – ou la consultation de forums d’aide aux développeurs – permet de se faire une idée de l’extrême liberté que confère le code.
#### 5.3 Connaissance du compilateur
N’oublions pas que le code assembleur n’est qu’une libre interprétation du code de haut niveau écrit par l’humain. Le compilateur a la charge de produire un code fonctionnellement identique, mais qui peut être structurellement très différent. Nous reviendrons plus tard sur les optimisations proposées par les compilateurs, mais si vous êtes du genre à encore penser que vous pouvez faire mieux qu’un compilateur moderne « à la main », arrêtez-vous et lisez immédiatement la formation de Rolf Rolles intitulée « *Binary Literacy – Optimizations and OOP* » **\[3]**.
La diversité des compilateurs s’est considérablement réduite ces derniers temps (il devient rare de rencontrer les compilateurs de Borland, Watcom ou Metrowerks). Les deux survivants sont GCC et Visual Studio – avec LLVM en *challenger*, et une mention spéciale pour le compilateur Intel (ICC), qui est capable de produire du code incroyablement optimisé – et donc totalement illisible.
Même s’il ne reste que deux compilateurs, il n’en reste pas moins que la liste des options de compilation proposées par GCC laisse rêveur **\[4]**. Or, le niveau d’optimisation, les options finline\*, funroll\* ou fomit-frame-pointer vont avoir des effets considérables sur le code généré.
#### 5.4 Reconnaissance de forme
C’est probablement la qualité essentielle du bon reverser. Après des milliers d’heures d’apprentissage, son cerveau reconnaît immédiatement toutes les structures « classiques », de la boucle « for »… à l’implémentation DES en boîte blanche.
Je ne prétends absolument pas jouer dans cette catégorie – c’est d’ailleurs pour cela qu’on ne m’a confié que l’introduction – mais je crois qu’il m’a été donné d’approcher des gens réellement hors du commun dans le domaine. Et je peux vous dire que c’est beau comme un concert de Rammstein.
Ce qui nous amène à la conclusion essentielle : seul un conditionnement du cerveau à l’âge où sa plastique est maximale permet de produire un reverser d’exception. Si les Chinois mettent en place des camps d’entraînement, on peut commencer à craindre pour notre propriété intellectuelle. Et si la sécurité informatique espère encore recruter dans 10 ans, il serait temps de mettre au programme du collège.
### 6. Another World
#### 6.1 Analyse statique ou analyse dynamique ?
Les puristes vous diront que le vrai « reverser » ne fait que de l’analyse statique, c’est-à-dire de la lecture de code mort (éventuellement couplée à un peu d’exécution symbolique). Il est vrai que cette approche est parfois la seule envisageable, par exemple lorsque la plateforme matérielle n’est pas disponible ou débogable (ex. systèmes SCADA).
Néanmoins, je ne serai pas aussi intransigeant et je vous présenterai l’autre approche moins élégante, mais plus « *quick win* » : il s’agit de l’analyse dynamique.
En effet, l’observation du logiciel en cours d’exécution permet d’identifier rapidement ses fonctions essentielles en « boîte noire ». Des outils comme Process Monitor, APIMonitor ou WinAPIOverride32 s’avèrent indispensables.
#### 6.2 Démarche pour l’analyse statique
Une démarche de reverse efficace ne commence *pas* bille en tête par la lecture du code assembleur. D’autres éléments plus facilement observables donnent rapidement des pistes essentielles.
* Sections
Cela peut sembler une évidence, mais si votre cible contient 3 sections nommées UPX0, UPX1 et UPX2, vous gagnerez un temps précieux à utiliser la commande upx -d plutôt que d’exécuter pas-à-pas le programme depuis le point d’entrée **\[5]**…
Il faut également prêter attention au développeur malicieux, qui utilise une version modifiée du logiciel UPX pour induire en erreur l’analyste. C’est pourquoi des outils d’identification (tels que PEiD) proposent de rechercher les signatures applicatives des « packers » les plus courants.
* Imports/exports
La liste des fonctions importées – lorsqu’elle est disponible – permet rapidement de se faire une idée des parties essentielles du programme : cryptographie, génération d’aléa, accès au réseau, etc.
Dans l’hypothèse où l’application cible prend une « empreinte » de la plateforme matérielle pour générer un numéro d’installation unique par exemple, identifier les fonctions GetAdaptersAddresses() ou GetVolumeInformation() dans les imports donne des points d’entrée intéressants…
* Constantes
La plupart des algorithmes reposent sur des constantes « bien connues » : la chaîne de caractères KGS!@#$% pour la génération des hashes LM, les constantes 0x67452301 0xEFCDAB89 0x98BADCFE 0x10325476 pour MD5, etc.
D’autre part, de nombreuses implémentations « optimisées » reposent également sur des tableaux pré-calculés : c’est le cas pour DES, tous les algorithmes de CRC, etc.
Enfin, la plupart des algorithmes disposent d’une structure identifiable (nombre de tours, ordre des décalages, etc.).
* Chaînes de caractères
Les chaînes de caractères sont des constantes particulières. Il n’existe pas de méthode scientifique pour explorer les chaînes de caractères, mais l’œil humain repère rapidement les chaînes « intéressantes » : chaînes encodées en Base64 ou en ROT13, chaînes donnant des indications d’usage (comme User-Agent : Mozilla/4.0 ou BEGIN RSA PRIVATE KEY), copyrights, références au code source, messages de débogage, etc.
* Bibliothèques et code open source
Force est de constater que les développeurs adorent la réutilisation de code, comme l’a encore démontré la récente faille dans libupnp. OpenSSL, Boost, ZLib et LibPNG font également partie des suspects habituels. La présentation d’Antony Desnos sur les applications Android laisse rêveur, sachant que certaines applications se composent à 95% de code publicitaire !
Il est donc strictement indispensable d’élaguer tout le code provenant des librairies standards fournies avec le compilateur, et tout le code issu des projets open source, avant de se concentrer sur la partie essentielle du code.
Il n’existe pas d’approche universelle dans le domaine, mais il existe au moins deux pistes intéressantes : la génération de signatures pour IDA avec l’outil FLAIR **\[6]**, et l’outil BinDiff **\[7]**. Ce dernier étant basé sur la comparaison de graphes, il est indépendant du langage assembleur : il est donc théoriquement possible de compiler OpenSSL sur Linux/x86, puis d’identifier les fonctions correspondantes dans un binaire Android/ARM par exemple.
Il existe des projets visant à mutualiser l’échange de signatures entre « reversers », comme par exemple CrowdRE **\[8]**.
* Métadonnées
Selon les technologies utilisées, le compilateur peut intégrer dans le binaire des métadonnées parfois très intéressantes : informations de débogage, données RTTI pour le C++ (voire à ce sujet l’article de Jean-Philippe LUYTEN dans MISC n°61), *stubs* des interfaces MS-RPC (cf. plugin mIDA), etc.
* Traces et modes de débogage
De (trop) nombreux logiciels disposent de fonctions de journalisation qui peuvent être réactivées par une configuration spécifique (clé de base de registre, variable d’environnement, conjonction astrale, etc.). La sortie de cette journalisation peut s’effectuer dans un fichier texte, un fichier au format Windows ETL, un débogueur attaché au processus, etc.
Non seulement les chaînes de caractères associées à ces fonctions vont livrer des informations précieuses pour l’analyse statique (comme les types ou les noms des champs dans les structures de données), mais ces traces vont également considérablement accélérer l’analyse dynamique.
Je crois qu’on sous-estime grandement la valeur des versions « *Checked Build* » de Windows disponibles aux abonnés MSDN…
#### 6.3 Théorie de la compilation
Passons en revue quelques techniques « classiques » d’optimisation qu’il est de bon ton de connaître.
* Alimentation du « *pipeline* » et prédiction de branchement
Les processeurs modernes pratiquent la divination : ils exécutent des instructions au-delà de la valeur courante du pointeur d’instruction (exécution spéculative), dans l’ordre qui leur paraît le plus efficace (ré-ordonnancement). Cette optimisation est très efficace sur des instructions arithmétiques indépendantes - d’autant que le compilateur va entremêler les instructions (*scheduling*) et allouer les registres en conséquence - mais se heurte au problème des sauts conditionnels.
La majorité des sauts conditionnels étant corrélés à l’implémentation d’une boucle, le processeur applique l’heuristique suivante : les sauts en arrière sont généralement pris, tandis que les sauts en avant ne sont généralement pas pris. Si le processeur s’est trompé dans sa prédiction, il doit annuler le commencement d’exécution de toutes les instructions qui ne seront finalement pas exécutées, ce qui est très coûteux.
Le compilateur connaît cette heuristique, ce qui lui permet d’optimiser les boucles et les tests conditionnels.
Sur architectures Intel x86 et x64, il est possible de contrôler la prédiction de branchement via des registres de configuration, voire d’enregistrer tous les branchements dans un *buffer* circulaire (*Branch Trace Store*) à des fins de *profiling*.
Sur architecture ARM, toutes les instructions sont conditionnelles, ce qui permet des optimisations intéressantes, comme la suppression des sauts conditionnels pour les assignations simples (de type opérateur ternaire).
Le Pentium Pro (architecture P6) a introduit l’instruction d’assignation conditionnelle CMOV, qui permet le même type d’optimisation. Il faut toutefois noter que le gain en performance n’est pas automatique, et que d’autres astuces (comme l’instruction SBB, qui prend en compte la valeur du « *Carry Flag* ») permettaient déjà des optimisations.
* Le déroulement de boucle
La meilleure solution pour éviter le coût des sauts conditionnels… c’est de les supprimer purement et simplement !
Si le compilateur connaît à l’avance le nombre d’itérations dans une boucle, et que le code généré peut tenir entièrement dans une page de code (soit 4 Ko sur architectures x86/x64), alors le compilateur copie/colle le code de la boucle autant de fois que nécessaire.
Cette construction est très courante dans les séquences d’initialisation d’algorithmes cryptographiques. Le code généré semble anormalement long de prime abord, mais s’analyse très rapidement.
* L’alignement
Par conception des microcircuits, il est beaucoup plus efficace de travailler à la taille native des mots du processeur. Par exemple, une implémentation naïve de memcpy() pourrait être :
for (i=0 ; i < len ; i++) dst\[i] = src\[i] ;
Aucune librairie C ne propose une implémentation aussi médiocre : travailler octet par octet sur un bus de 32 bits, c’est diviser par 4 la performance. Une meilleure implémentation de memcpy() serait la suivante :
1. En amont, s’assurer que dst et src sont alloués à des adresses multiples de 4. Si les deux tableaux sont alignés sur 4 Ko et occupent donc un nombre minimal de pages en mémoire, c’est encore mieux.
2. Copier len / 4 mots de 32 bits.
3. Copier les len % 4 octets restants.
C’est en substance l’implémentation qu’on trouve dans la librairie C de Windows XP (MSVCRT.DLL).
Bien entendu, des algorithmes plus complexes s’optimisent encore mieux. Je vous invite par exemple à consulter l’implémentation de la fonction strlen() dans la librairie C du projet GNU (mais pas celle de BSD, qui est naïve).
Si vous êtes sensible à la beauté du code, voici l’implémentation réelle de strlen() sur Mac OS 10.7 (64 bits), telle que représentée par l’outil otool :
\_strlen:
pxor %xmm0,%xmm0
movl %edi,%ecx
movq %rdi,%rdx
andq $0xf0,%rdi
orl $0xff,%eax
pcmpeqb (%rdi),%xmm0
andl $0x0f,%ecx
shll %cl,%eax
pmovmskb %xmm0,%ecx
andl %eax,%ecx
je 0x000a250b
00000000000a2501:
bsfl %ecx,%eax
subq %rdx,%rdi
addq %rdi,%rax
ret
00000000000a250b:
pxor %xmm0,%xmm0
addq $0x10,%rdi
00000000000a2513:
movdqa (%rdi),%xmm1
addq $0x10,%rdi
pcmpeqb %xmm0,%xmm1
pmovmskb %xmm1,%ecx
testl %ecx,%ecx
je 0x000a2513
subq $0x10,%rdi
jmp 0x000a2501
* « *Inlining* »
Comme les sauts conditionnels, l’appel de fonction est une opération excessivement coûteuse, surtout si la destination ne se trouve pas dans la même page de code.
On notera au passage que le noyau Windows – ainsi que le logiciel Chrome **\[9]** – font l’objet d’une optimisation post-compilation, qui consiste à regrouper le code le plus souvent exécuté dans quelques pages mémoire, plutôt que de le répartir dans tout le binaire (optimisation dite « OMAP » **\[10]**). Il est même optimal d’aligner le code sur la taille des lignes du cache d’instruction, soit 16 octets sur architectures x86 et x64.
Afin de limiter les appels de fonction, le compilateur peut décider d’inclure le code de la sous-routine directement sur son lieu d’appel, comme dans les exemples ci-dessous.
| 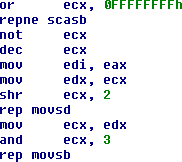
strcpy()
| 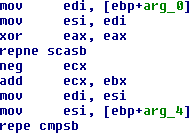
strcmp()
|
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
Notez l’utilisation des instructions SCAS/MOVS/CMPS associées au préfixe REP, plutôt qu’une construction de boucle beaucoup moins performante.
* Les instructions interdites
Certaines instructions sont peu ou pas utilisées par les compilateurs. Il s’agit d’une optimisation liée au temps d’exécution de ces instructions. Par exemple, l’instruction LOOP nécessite 6 cycles d’horloge en cas de branchement sur processeur 80486. La séquence DEC ECX / JNZ xxx ne nécessite que 1 + 3 cycles pour la même opération.
A contrario, l’instruction LEA est couramment utilisée pour effectuer des additions entre constantes et registres, alors que ça n’est pas sa fonction première.
La situation se complique encore, car le nombre de cycles par instruction est très variable d’un processeur à l’autre. C’est pourquoi en fonction du processeur cible que vous spécifierez au compilateur Intel ICC, vous obtiendrez un code sensiblement différent…
* Multiplication et division
La multiplication et la division par une puissance de 2 s’implémentent par un simple décalage de bits : ce sont des opérations simples. Les mêmes opérations avec des opérandes arbitraires sont des opérations excessivement coûteuses. À titre d’exemple, voici les durées d’exécution (en nombre de cycles d’horloge) de quelques instructions sur un processeur 80486 :
| Opération | Opérande | Cycles |
| -------------- | ------------------- | ------- |
| Multiplication | IMUL \ | 12 à 42 |
| | MUL \ | 13 à 42 |
| Division | DIV \ | 40 |
| | IDIV \ | 43 |
| Décalage | SHL \, \ | 2 |
| Addition | ADD \, \ | 1 |
Pour multiplier X par 12, le compilateur va donc découper l’opération de la manière suivante : (X\*8) + (X\*4).
Pour diviser un nombre X sur 32 bits par 17, le compilateur peut être tenté d’utiliser la multiplication réciproque.
Selon l’algorithme d’Euclide étendu, l’inverse de 17 modulo 2^32 est 4042322161. Il suffit donc de multiplier X par ce nombre (modulo 2^32) pour obtenir le résultat de la division.
#### 6.4 Pratique de la décompilation
La compilation en langage assembleur provoque la perte d’informations essentielles, telles que le type de données. La décompilation (retour au code source d’origine) s’avère donc être un problème difficile. Ce domaine a stimulé de nombreux travaux universitaires, qui sont pour la plupart restés du niveau de la « preuve de concept ».
Loin du Latex et autres CiteSeer, un maître du reverse engineering - auteur du logiciel IDA Pro – s’est un jour attaqué au problème. Combinant l’abondante théorie sur le sujet avec sa pratique de la chose et de nombreuses heuristiques par compilateur, il fabriqua par un matin blême la Pierre Philosophale de la décompilation : Hex-Rays Decompiler **\[11]**.
Aujourd’hui, cet outil intégré à IDA Pro décompile de manière tout à fait correcte les assembleurs x86 et ARM, supporte l’enrichissement manuel du listing, mais permet également le débogage au niveau du code source reconstitué. Il justifie donc largement son coût d’acquisition, relativement modique pour une entreprise.
**Source** :

